Note: You may be interested in DocFetcher Pro, the commercial big brother of DocFetcher with more features and fewer bugs, or DocFetcher Server, the commercial cousin of DocFetcher with multi-user support and a web interface. Find out more.
Descripción
DocFetcher es una aplicación Open Source de búsqueda de escritorio: Permite que busques contenidos de ficheros en tu ordenador. — Puedes verlo como una especie de Google para tus ficheros locales. La aplicación funciona en Windows, Linux y OS X, y está disponible bajo la Licencia Eclipse Public.
Uso Básico
La siguiente captura de pantalla muestra el interfaz de usuario principal. Las consultas se introducen en el campo (1). Los resultados de la búsqueda se muestran en el panel de resultados (2). El panel de vista previa (3) muestra una versión sin formato (sólo texto) del fichero seleccionado in el panel de resultados. Todas las coincidencias en el archivo están resaltadas en amarillo.
Puede filtrar los resultados por el tamaño máximo y/o mínimo del fichero (4), por tipo de fichero (5) y por ubicación (6). Los botones en (7) sirven para abrir el manual, las preferencias y para minimizar el programa a la barra de tareas respectivamente.

DocFetcher necesita los llamados índices para las carpetas en las que quieras realizar búsquedas. Qué indexa y cómo lo hace está explicado en detalle más abajo. En pocas palabras, un índice le permite a DocFetcher buscar muy rápido (del orden de milisegundos) qué ficheros contienen unas palabras concretas, acelerando enormemente la velocidad de las búsquedas. Las siguientes capturas de pantalla muestran el cuadro de diálogo de DocFetcher para crear nuevos índices:
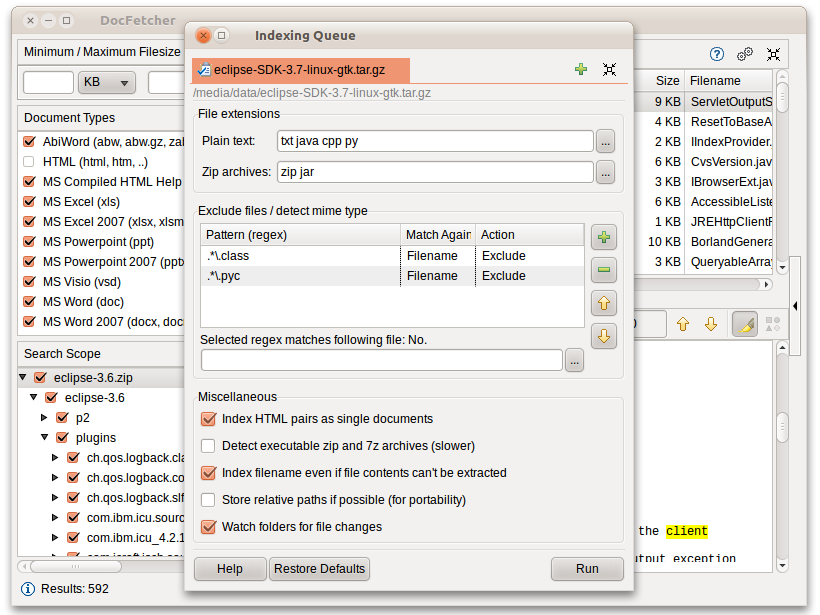
Pulsando el botón de "Ejecutar" en la parte inferior derecha del cuadro de diálogo pone en marcha la indexación. El proceso de indexación puede tardar un rato, dependiendo del número y el tamaño de los ficheros a indexar. Aproximadamente podría procesar unos 200 ficheros por minuto.
Aunque tarda tiempo en crear el índice, sólo hay que hacerlo una vez por carpeta. *Actualizar" un índice cuando cambian los contenidos de la carpeta es mucho más rápido que crearlo — normalmente solo tarda un par de segundos.
Características Destacadas
- Versión portable: Hay una versión portable de DocFetcher que funciona en Windows, Linux y OS X. Más adelante, en esta misma página, se explica por qué es esto útil.
- Soporte para 64-bit: Están soportados los sistemas operativos de 32-bit y 64-bit.
- Soporte Unicode: DocFetcher tiene un sólido soporte Unicode para los formatos más importantes, incluyendo Microsoft Office, OpenOffice.org, PDF, HTML, RTF y ficheros de texto plano.
- Ficheros soportados: DocFetcher soporta los siguientes formatos de fichero: zip, 7z, rar, y toda la familia tar.*. Las extensiones de los ficheros zip se pueden modificar, permitiendo así añadir más ficheros en formato zip según sea necesario. DocFetcher también puede gestionar un número ilimitado de ficheros anidados (por ejemplo un fichero zip que contiene un fichero 7z que contiene a su vez un fichero rar.... etc.)
- Búsqueda en ficheros de código fuente: Las extensiones que DocFetcher reconoce como ficheros de texto plano se pueden modificar, por lo que puedes usar DocFetcher para buscar cualquier tipo de código fuente y otros tipos de ficheros en formtato de texto plano. (Esto funciona muy bien en combinación con las extensiones zip modificables, por ejemplo para buscar código fuente de Java dentro de ficheros .jar).
- Ficheros PST de Outlook: DocFetcher permite la búsqueda de correos electrónicos de Outlook, los cuales Microsoft Outlook normalmente almacena en ficheros PST .
- Detección de pares HTML: Por defecto, DocFetcher detecta los pares de ficheros HTML ( por ejemplo un fichero llamado "foo.html" y una carpeta llamada "foo_files"), y trata los pares como un único documento. Esta característica puede parecer poco útil al principio, pero como resultado se incrementan enormemente la calidad de las búsquedas al trabajar con ficheros HTML, ya que el "lío" dentro de las carpetas HTML desaparece de los resultados.
- Regex-based exclusion of files from indexing: You can use regular expressions to exclude certain files from indexing. For example, to exclude Microsoft Excel files, you can use a regular expression like this:
.*\.xls - Detección de tipo mime: Puede usar expresiones regulares para activar la "detección de tipo mime" para ciertos ficheros, de manera que DocFetcher tratará de detectar el tipo de ficheros no sólo por el nombre de fichero, sino también comprobando el contenido del fichero. Esto resulta últil para ficheros que tienen una extensión incorrecta.
- Potente sintaxis de consulta : Además de las construcciones básicas como
OR,ANDyNOTDocFetcher también soporta, entre otras cosas: Comodines, búsqueda de frases, búsquedas vagas ("buscar palabras que son similares a..."), búsqueda de proximidad ("estas dos palabras deben estar al menos separadas por 10 palabras"), incrementos ("incrementar la calificación de los documentos que contienen...")
Formatos de Documentos Soportados
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 and newer (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- HTML (html, xhtml, ...)
- Texto plano (customizable)
- Formato de Texto Enriquecido (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Comparación Con Otras Aplicaciones De Búsqueda De Escritorio
En comparación con otras aplicaciones de búsqueda de escritorio, estas son las razones por las que DocFetcher destaca:
Libre de estupideces: Nos esforzamos en mantenet el interfaz de usuario de DocFetcher libre de líos y estupideces. Sin anuncios ni ventanas emergentes de "¿le gustaría registrarse....?". Sin cosas inútiles instaladas en su navegador, registro ni en ninguna otra parte de su sistema.
Privacidad: DocFetcher no recopila tu información privada. Nunca. Cualquiera que tenga dudas puede consultar el código fuente disponible públicamente.
Gratis para siempre: Como DocFetcher es Open Source, no tienes que preocuparte porque el programa se quede obsoleto y sin soporte, ya que el código fuente estará siempre disponible. Hablando de soporte, ¿se ha enterado por las noticias de que Google Desktop, uno de los principales competidores comerciales de DocFetcher, fue discontinuado en 2011? Bien...
Multiplataforma: A diferencia de muchos de nuestros competidores, DocFetcher no funciona sólo en Windows, sino que también lo hace en Linux y OS X. Por lo que si en algún momento le apetece dejar Windows y cambiar a Linux o OS X, DocFetcher estará esperándole al otro lado.
Portable: Una de las mayores fortalezas de
Indexando sólo lo que necesita: Entre los competidores comerciales de DocFetcher, parece haber una tendencia a animar a los usuarios a indexar por completo el disco duro — quizá en un intento de evitar todas las decisiones posibles a un usuario supuestamente "torpe", o peor aún, en un intento recopilar más datos de usuario. En la práctica parece seguro asumir que la mayoría de la gente no quiere indexar tu disco duro completo. No sólo es un derroche de tiempo de indexación y espacio de disco, sino que también complica los resultados de búsqueda con ficheros no deseados. Por tanto, DocFetcherindeza sólo las carpetas que explícitamente desea indexar, además dispone de multitud de opciones de filtrado.
Repositorios de Documentos Portables
One of DocFetcher's outstanding features is that it is available as a portable version which allows you to create a portable document repository — a fully indexed and fully searchable repository of all your important documents that you can freely move around.
Usage examples: There are all kinds of things you can do with such a repository: You can carry it with you on a USB drive, burn it onto a CD-ROM for archiving purposes, put it in an encrypted volume (recommended: TrueCrypt), synchronize it between multiple computers via a cloud storage service like DropBox, etc. Better yet, since DocFetcher is Open Source, you can even redistribute your repository: Upload it and share it with the rest of the world if you want.
Java: Performance and portability: One aspect some people might take issue with is that DocFetcher was written in Java, which has a reputation of being "slow". This was indeed true ten years ago, but since then Java's performance has seen much improvement, according to Wikipedia. Anyways, the great thing about being written in Java is that the very same portable DocFetcher package can be run on Windows, Linux and OS X — many other programs require using separate bundles for each platform. As a result, you can, for example, put your portable document repository on a USB drive and then access it from any of these operating systems, provided that a Java runtime is installed.
Cómo Funciona La Indexación
Esta sección trata de explicar de una manera básica qué es la indexación y cómo funciona.
The naive approach to file search: The most basic approach to file search is to simply visit every file in a certain location one-by-one whenever a search is performed. This works well enough for filename-only search, because analyzing filenames is very fast. However, it wouldn't work so well if you wanted to search the contents of files, since full text extraction is a much more expensive operation than filename analysis.
Index-based search: That's why DocFetcher, being a content searcher, takes an approach known as indexing: The basic idea is that most of the files people need to search in (like, more than 95%) are modified very infrequently or not at all. So, rather than doing full text extraction on every file on every search, it is far more efficient to perform text extraction on all files just once, and to create a so-called index from all the extracted text. This index is kind of like a dictionary that allows quickly looking up files by the words they contain.
Telephone book analogy: As an analogy, consider how much more efficient it is to look up someone's phone number in a telephone book (the "index") instead of calling every possible phone number just to find out whether the person on the other end is the one you're looking for. — Calling someone over the phone and extracing text from a file can both be considered "expensive operations". Also, the fact that people don't change their phone numbers very frequently is analogous to the fact that most files on a computer are rarely if ever modified.
Index updates: Of course, an index only reflects the state of the indexed files when it was created, not necessarily the latest state of the files. Thus, if the index isn't kept up-to-date, you could get outdated search results, much in the same way a telephone book can become out of date. However, this shouldn't be much of a problem if we can assume that most of the files are rarely modified. Additionally, DocFetcher is capable of automatically updating its indexes: (1) When it's running, it detects changed files and updates its indexes accordingly. (2) When it isn't running, a small daemon in the background will detect changes and keep a list of indexes to be updated; DocFetcher will then update those indexes the next time it is started. And don't you worry about the daemon: It has really low CPU usage and memory footprint, since it does nothing except noting which folders have changed, and leaves the more expensive index updates to DocFetcher.








